【DCSSの最強ビルド】あらゆるデュアルは石像格闘を目指すべし【ゲームバランス破壊注意】
DCSS 0.29がリリース(0.29 “Shooting Stars” « Dungeon Crawl Stone Soup)され、現在絶賛トーナメント期間中です。
とりあえずTake1で1勝したものの、その後調子に乗ってもっと強いキャラで複合バナー等狙おうとしたら再序盤であっさり敗北。
その次も0.29特有の微妙ビルドに再挑戦をと思ったらまた序盤で敗北、とやる気を失っているところ。
まあトナメはもういいか、という感じです。新種族Meteorun?には全く現状触れていないので、トナメ関係なくそのうちプレイするかもしれません。
なお、勝ったダンプは抜粋すると下記の通り。
今回の記事タイトルとも関係しているので、スキル欄含めて、特に見て欲しいところを
見にくいですが載せてみます。
ダンプ全文見たいという奇特な方は元リンク(http://lazy-life.ddo.jp:8000/morgue-0.29/radinms/morgue-radinms-20220827-120934.txt)
を是非見てください。そんな人はまあいないと思いますが・・・。
このキャラについては、記事の最後に雑感含めて少しだけ触れることになるでしょう。
Dungeon Crawl Stone Soup version 0.29.0-4-gdea44cf6ec (webtiles) character file.
Game seed: 9500401389923257600
1866466 radinms the Sensei (level 27, 487/487 HPs)
Began as an Octopode Ice Elementalist on Aug 27, 2022.
Was an Initiate of Gozag.
Escaped with the Orb
... and 4 runes!
The game lasted 04:54:41 (104761 turns).
radinms the Sensei (Octopode Ice Elementalist) Turns: 104761, Time: 04:54:42
Health: 487/487 AC: 16 Str: 26 (27) XL: 27
Magic: 42/46 EV: 26 Int: 24 God: Gozag
Gold: 2149 SH: 0 Dex: 27 Spells: 8/55 levels leftrFire + + + SeeInvis . - Unarmed
rCold + . . Faith . (shield currently unavailable)
rNeg + + . Spirit + (helmet currently unavailable)
rPois + Reflect . v - amulet of guardian spirit
rElec + Harm . N - +6 ring of dexterity
rCorr . Rampage . e - ring of protection from fire
Will ++++. P - ring of protection from fire
Stlth .......... C - ring of magical power
HPRegen 0.91/turn y - ring "Ofov" {Fly rC+ Will+}
MPRegen 0.30/turn i - ring of protection from fire
j - ring "Pefev" {rElec rC+ rN+ Stlth+}
d - ring of Insomnia {rN+ Will+ Str+3 Int+6}@: mighty, brilliant, berserking, dragon-form, flying, studying Axes, very quick
A: dragon claw, dragon scales, breathe fire, flying, boosted hp, almost no
armour, amphibious, 8 rings, giant, (camouflage 1), (gelatinous body 1), (nimble
swimmer 1), (tentacles), deterioration 1, low MP 1, robust 1, strong 1, subdued
magic 1
}: 4/15 runes: barnacled, slimy, silver, gossamerSkills:
+ Level 18.9 Fighting
- Level 8.4 Short Blades
- Level 6.3 Throwing
* Level 20.8 Dodging
- Level 12.6 Stealth
- Level 11.2 Shields
* Level 22.5 Unarmed Combat
- Level 14.8 Spellcasting
- Level 6.1 Conjurations
- Level 3.6 Hexes
- Level 8.4 Necromancy
- Level 12.1 Translocations
- Level 15.6 Transmutations
- Level 10.0 Ice Magic
- Level 4.0 Air Magic
- Level 10.1 Earth Magic
- Level 10.9 EvocationsYour Spells Type Power Damage Failure Level
a - Freeze Ice 100% 1d11 1% 1
b - Frozen Ramparts Ice 100% 1d16 1% 3
c - Ozocubu's Armour Ice 66% N/A 1% 3
d - Dragon Form Tmut 41% N/A 3% 7
e - Ensorcelled Hibernat Hex/Ice 100% N/A 1% 2
f - Mephitic Cloud Conj/Pois/Air 39% N/A 1% 3
g - Passage of Golubria Tloc 72% N/A 1% 4
h - Borgnjor's Vile Clut Necr/Erth 32% N/A 1% 5
i - Blink Tloc 100% N/A 0% 2
j - Manifold Assault Tloc 72% N/A 1% 5
k - Freezing Cloud Conj/Ice/Air 27% 6-21 4% 5
s - Statue Form Tmut/Erth 50% N/A 1% 6
x - Apportation Tloc 100% N/A 0% 1
さて、直近の勝ったダンプ自慢は終わり、記事本題に入りましょう。
本記事は、スキル性による自由なビルド構築が売りのRoguelikeゲームことDCSSにおける、最もビルドをゆがませる魔法"Statue Form"をフル活用した、いわゆる「石像格闘ビルド」への理解を深めることを目的としています。
個々のプレイにおける戦術的立ち回りを指南する記事ではなく、大局的なビルド構築という戦略的要素を解説する記事であり、昨日・今日DCSSを始めた人、まだ一度も脱出していない人、また、Trogを唯一絶対の神と崇め、他の邪教を一切信仰しない人が理解できる内容とはなっていません。
また、初脱出後、あれこれ試行しながら別のビルドを模索・構築中の人にとっては、ゲームの魅力が一部スポイルされるかもしれませんし、あるいは、このゲームに対する価値観が完全に破壊されてしまうかもしれません。
さらに、もしあなたがTA勢(ちなみに私はTA製ではない)であるのならば、周知の事実ばかりの内容でもあり、読むのは時間の無駄かもしれません。
前置きが長くなりましたが、その点を了承いただける方のみ、以降の説明をお読みください。
【① "Statue Form"とは何か? 「石像格闘」とは?】
DCSSの最強魔法は何か、と聞かれたら、私は真面目に"Statue Form"を挙げます。
この魔法はね、ビルドを歪ませるんです。「決め打ちで今回のキャラは~を使ってクリアする」といった明確なコンセプトを持たず、「久しぶりにこのゲーム触るしとりあえず勝てばいい」とか「引きに応じて柔軟にビルドを構築していく」といったキャラの場合、もしStatue Formを引いてしまったら、Statue Formを使用する誘惑に抗うことは、私には到底できません。
では、Statue Formとはどんな魔法か説明しますと、高レベルの変異魔法(地/変異Lv6)です。身体が石像に変わります。
どんな効果か英wiki(Statue Form - CrawlWiki)から抜粋してみます。
Pros
- Unarmed Combat Base Damage = UC+12
- +50% damage bonus to all melee attacks
- A huge AC bonus (20 + (spell power)/12, max 37)
- +30% HP
- Immunity to poison & miasma
- Electricity resistance
- One rank of negative energy resistance
- 50% reduction to torment damage (stacks with rN)
Cons
- Body armour, gloves, and boots meld into your character, becoming inactive.
- Base movement delay is increased to 1.5.
- The base cost of all other actions is increased by 50% (like being slowed, stacks with slow)
- Vulnerability to Shatter and Lee's Rapid Deconstruction
要約すると、「素手が強くなるよ」「装備部位が色々剥がれる代わりにACと耐性がいっぱいつくよ」「HPも上がるよ」「全行動が1.5倍遅くなるよ(代わりに殴り火力は1.5倍だよ」。
恐ろしく強い。・・・・・・ということが、この抜粋だけで理解できた人は、以降の記事を読む必要はありません。回れ右。
いまいち強さがピンとこないという人は、続けて記事を読んでください。
一度もこの魔法を使ったことがない人は、なぜこんなに強いと言われるのか、疑問が尽きないのではないでしょうか。
「装備剥がれるとかクソ」「素手なんか使わねーし」「変異術は他にも一杯ある」「全行動が遅くなるってwwCheiでさえ遅くなるのは移動だけなのにww」などなど。
以降は、Statue Formの真価が何なのかをズバリ説明し、これらの疑問へ回答していきます。
【② "Statue Form"の真価は何か?】
Statue Formの真価、それは圧倒的な防御力にあります。
DCSSはしっかりとした防御力を確保できれば、劇的に難易度が低下します。逆に、防御力を確保できないと、どれだけ火力が高くても安定したプレイは難しいのです。
(統計をしっかり取ったわけではありませんが、DCSSはダメージを与える機会よりダメージを受ける機会の方が圧倒的に多い気がしています)
防御力なんて気にしたことない、という人は、プレイが極端に上手いか、あるいは普段から防御力を比較的確保できるキャラばかりプレイしているためにその恩恵に気づけていないか、どちらかだと思います。
前者については、繰り返しになりますが、本記事は、局所的な最適戦術を指南するものではなく、より安定した戦略を考察するものですので、防御力を伸ばすことを前提として以降解説を進めていきます。
後者については、最終的に金竜鎧を着込むような、いわゆる「重戦士ビルド」が想定されているように思います。
確かに、重戦士ビルドは、文字通り比較的硬いビルドではありますが、DCSSのビルドというのは重戦士だけではなく、術士やデュアルというビルドもあります。
そうしたビルドは、(魔法詠唱の成功率を低下させる)鎧を着込むことが難しいため、重戦士と比較して防御力の確保に難のある展開が多く、Statue Formはまさに救世主ともいえる魔法なのです。
(どれくらい救世主かというと、全行動が遅くなるデメリットが全く気にならないレベル)
また、魔法を一切使用しない重戦士よりも、Statue Formを使用するデュアルの方が、防御力が高くなるケースも多々あるのです(特に全能神Cheiを崇めている場合等)。
【③ 素手で戦わないといけないのか?】
Statue Formの圧倒的な防御力の話は理解したとして、次に疑問として出てくるのは「素手を使わないといけないのか?」ではないでしょうか。
DCSSは武器を装備して戦うビルドが通常であり、変異術を駆使して素手で戦うビルドはマイナービルドです。
そんなマイナービルドでしか使えない魔法が最強といわれても・・・と思う人もいるかもしれません。
この疑問への回答は、まず第一には「Statue Formは素手を選択しないあらゆるビルドで強力な選択肢」です。
変異術の中でも、Blade HandsやDragon Formが武器を剥がすため実質素手専用なのに対し、Statue Formは武器は剥がさないため、素手を鍛えず武器をもって戦う通常のビルド構築が可能です。
いわば、武器で戦う通常の軽装デュアルに一見見えながら、実は防御力が凄く高い、という状態になるため、非常に安定感のあるゲーム進行となるのです。
これが第一の回答なわけですが、第二の回答として、本記事で強く主張するのは、「うまく素手に転向してください」ということです。
DCSSにおいて、武器スキルの転向は全く推奨されていません(暗殺ビルド時の短剣→長剣を除く)し、私も一切推奨しません。
それは至極当然の話で、「短剣以外はスキルを鍛え上げれば劇的な火力の差はない」「武器スキルはかなり振らないといけないため転向は非現実的」といった理由があり、しかも、「なぜかゲームシステムを理解していない初心者ほど謎の武器転向をしたがる」現象が多々観察されており、海外のDCSSフォーラムで武器の転向についてアドバイスでも求めようものなら、上級者から強く一蹴されるのがオチでしょう。
しかし、変異術によるブーストをかけた素手の火力は最強です。横並びの武器とは違い、劇的な火力の差があります。
最強の火力を得られるパーツを手に入れているのに、それをむざむざ無視するという選択は非常に勿体ない、というのが個人的見解です。
【④ スキルの転向は現実的なのか?】
火力が武器を遙かに上回るため、素手へ転向すべしと上述したわけですが、さてさて果たしてそれは現実的なのでしょうか?
これについては論より証拠です。石像格闘ビルドばかりプレイしている私のダンプをいくつかお見せしましょう。
まず一つは、記事のトップに記載したタコのダンプ。氷の精霊使いでスタートし、短剣暗殺から無事石像格闘(Dragon Formも使用)ビルドへ転向しています。
次は、少し前のバージョンになりますが、人間のダンプ。火の精霊使いでスタートし、長剣使いから無事石像格闘ビルドへ転向しています。
http://lazy-life.ddo.jp:8000/morgue/radinms/morgue-radinms-20200502-054004.txt
Skills:
+ Level 21.9 Fighting
Level 9.5 Long Blades
Level 3.2 Axes
- Level 7.2 Armour
- Level 13.5 Dodging
- Level 10.3 Stealth
- Level 15.2 Shields
O Level 27 Unarmed Combat
- Level 15.3 Spellcasting
- Level 13.9 Conjurations
- Level 6.7 Summonings
- Level 8.6 Necromancy
- Level 8.7 Translocations
- Level 10.3 Transmutations
- Level 10.0 Fire Magic
Level 4.4 Air Magic
- Level 12.3 Earth Magic
- Level 13.0 Invocations
- Level 15.2 Evocations
これらは、いずれも早期にStatue Formを発見・転向しているため、転向前の武器スキルが低い状態です。
また、デュアルは、魔法をあれこれ伸ばす、軽装の防御力を補うため盾を鍛える(したがって重いスキルを要求しない片手武器となる)、などの理由から、そもそもの武器スキルが低くなりがちです。
しかし、武器スキルは高ければ高いほど安定するため、基本的には優先的に鍛えることを推奨します。上記2つのようなビルド構築は慣れないうちはあまり真似しないでください。慣れていれば全然やってもらって構わないです。
それでは、(ビルドの安定性のため)もっと武器スキルを鍛えているような場合はどうでしょうか。
さらに前のバージョンとなってしまいますが、こんなダンプがありました。もはや遠い記憶の彼方ですが、カエル火の精霊使いです。
http://lazy-life.ddo.jp:8000/morgue/radinms/morgue-radinms-20181027-071412.txt
Skills:
+ Level 16.0 Fighting
Level 16.8 Axes
- Level 6.7 Throwing
- Level 10.2 Armour
+ Level 11.4 Dodging
- Level 1.7 Stealth
- Level 16.2 Shields
* Level 24.8 Unarmed Combat
* Level 16.4 Spellcasting
- Level 11.1 Conjurations
- Level 8.7 Hexes
- Level 8.7 Charms
- Level 2.6 Necromancy
- Level 4.3 Translocations
- Level 9.3 Transmutations
- Level 6.7 Fire Magic
- Level 7.6 Ice Magic
* Level 21.1 Air Magic
+ Level 13.7 Earth Magic
- Level 13.1 Invocations
- Level 12.0 Evocations
カエルのスキル適性が高すぎるというのもあって、斧スキルを16以上伸ばしつつも素手への転向に成功しています。トルネードも使えるようになっているようです(一度も詠唱していないようですが・・・)。
以上のようなダンプを見てもらえれば、武器を使うデュアルから石像格闘への転向は現実的なものだと一定ご理解はいただけたのではないでしょうか。
【⑤ 最強火力を目指すなら、Statue Form以外の変異術はどうか?】
上記までの説明で、私の言いたいことはほぼ言い尽くしているのですが、まだ疑問は残っているかもしれません。
それは、最強火力を目指すなら、Statue Formではなく、Blade HandsやDragon Formの方がよいのでは? というもの。
(火力はStatue FormよりBlade HandsやDragon Formの方が高いため)
すなわち、武器を振りながら通常のデュアルとしてプレイし、Blade HandsやDragon Formを確保次第、素手へ転向するというプレイング。
これに関しては、決して弱くはないし有力な選択だとは思いますが、Statue Formと比較して防御力の確保がネックとなります。
繰り返しの説明となってしまいますが、DCSSは高い防御力を確保することが安定した攻略の要です。重戦士と比較した際のデュアルの難しさは主にここにあります。
その難しさを根底からひっくり返せるのがStatue Formです。Blade HandsやDragon Formではちっともひっくり返らないどころかかえって難しくなっている可能性さえあります。
具体的に説明すると、Blade HandsやDragon Formでは以下の点がネックとなります。
Statue Formをメインで使用しつつ、状況次第でBlade HandsやDragon Formを織り交ぜていくような戦い方は強いし面白いですが、まあ正直Statue Formだけで十分ですね・・・
・Blade Hands
盾装備不可(Statue Formは盾装備可のため、ACは当然としてそれ以外にも防御性能に差が出てくる)
魔法詠唱失敗率上昇(これがBlade Handsの真のデメリット。盾装備不可のため鎧でカバーしようなどと考えるとますます魔法詠唱が下手くそに。デュアルというよりもはや殴るしかできなくなる)
・Dragon Form
防御性能の大幅な低下(素のACは16に、+EV低下。装備は装身具以外剥がれ、rF++の代わりにrC-がつき、その点を忘れてると事故る)
火力は最強ですし防御力は低下するとはいえ全くなくなるわけではなく、HPも上がり魔法詠唱への影響もないため、Blade Handsより使いやすいかもしれません。
ちなみに、最近のDCSSではStorm Formという新たな変異術も追加されているのですが、一度も使ったことがないためこれについては言及ができません。
(まあ、あまり強いという評価は聞かないですが・・・)
【⑥ まとめ】
雑にまとめると、Statue Formは最強です。ゲームバランスをいとも簡単に破壊できます。
ある程度DCSSに慣れてきたら、術士スタートでデュアルとして戦いながら、Statue Formを引き次第素手へ転向するビルドがオススメです。
最後に、石像格闘ビルドの中でも、個人的最強ダンプを抜粋して終わりといたしましょう。
その名は、水棲の民氷の精霊使いChei信仰。
0.29リリース前の開発段階のダンプであり、氷魔法はこのプレイ以降に若干nerfされてしまいましたが、
それを考慮しても十二分に強い。
水棲の民はこの最強ビルドをプレイするためだけに存在するのかと、あまりのシナジーに嘆息せざるを得ません。
http://crawl.akrasiac.org/rawdata/radinms/morgue-radinms-20220724-121749.txt
Dungeon Crawl Stone Soup version 0.29-a0-902-g0f71de6 (webtiles) character file.
Game seed: 14787683029892816244
3445544 radinms the Grand Master (level 27, 249/249 HPs)
Began as a Merfolk Ice Elementalist on July 24, 2022.
Was the Champion of Cheibriados.
Escaped with the Orb
... and 5 runes!
The game lasted 04:17:59 (62709 turns).radinms the Grand Master (MfIE) Turns: 62709, Time: 04:18:00
Health: 249/249 AC: 15 Str: 28 XL: 27
Magic: 38/38 EV: 42 Int: 40 God: Cheibriados [******]
Gold: 4338 SH: 23 Dex: 38 Spells: 7/56 levels leftrFire + + + SeeInvis . - Unarmed
rCold + . . Faith . X - +5 kite shield {AC+3}
rNeg + . . Spirit + B - +4 moon troll leather armour {Spirit, Regen++ MP+5}
rPois . Reflect . D - +0 hat of Jeczapise {rN+ Regen+ MP-9 Str+4}
rElec + Harm . u - scarf {rC+ rF+}
rCorr . Rampage . z - +0 pair of gloves "Bewn" {Fly Regen+ Stlth-}
Will ++... W - +2 pair of boots of Angusm {rElec Str+2 Dex+3}
Stlth ++........ A - amulet "Sysyf" {RegenMP Fly Regen+}
HPRegen 4.51/turn S - ring "Birhinufa" {rF++ Slay+4}
MPRegen 0.66/turn d - ring "Boguzyug" {Wiz rElec Str-5 Int+8}@: flying, very slow
A: (nimble swimmer 2), mertail, deterioration 1, dopey 1, robust 1, inability to
read while threatened 1, sturdy frame 1
0: Orb of Zot
}: 5/15 runes: barnacled, slimy, silver, abyssal, gossamer
a: Renounce Religion, Bend Time, Temporal Distortion, Slouch, Step From Time
Skills:
* Level 20.8 Fighting
- Level 5.0 Long Blades
- Level 21.1 Dodging
- Level 7.0 Stealth
- Level 13.8 Shields
O Level 27 Unarmed Combat
- Level 15.2 Spellcasting
- Level 4.6 Conjurations
- Level 7.3 Translocations
- Level 14.3 Transmutations
- Level 25.5 Ice Magic
- Level 5.2 Air Magic
- Level 8.1 Earth Magic
- Level 13.0 Invocations
- Level 6.4 Evocations
You had 7 spell levels left.
You knew the following spells:Your Spells Type Power Damage Failure Level
a - Freeze Ice 100% 1d11 0% 1
b - Frozen Ramparts Ice 100% 1d12 0% 3
c - Blink Tloc 100% N/A 1% 2
d - Ozocubu's Armour Ice 100% N/A 0% 3
e - Apportation Tloc 100% N/A 1% 1
f - Lesser Beckoning Tloc 73% N/A 1% 3
g - Manifold Assault Tloc 73% N/A 1% 5
h - Freezing Cloud Conj/Ice/Air 45% 6-21 1% 5
i - Ozocubu's Refrigerat Ice 62% 4d17 1% 7
k - Passage of Golubria Tloc 73% N/A 1% 4
p - Polar Vortex Ice 62% N/A 2% 9
z - Statue Form Tmut/Erth 58% N/A 1% 6<<
フェイの最終問題を初クリアした話
本記事は、Roguelike Advent Calendar 2021 - Adventarの12/18の記事です。
スマホ版風来のシレンの「フェイの最終問題」を初クリアできましたので、そのことについて書きます。
内容的には薄い記事ですみません。
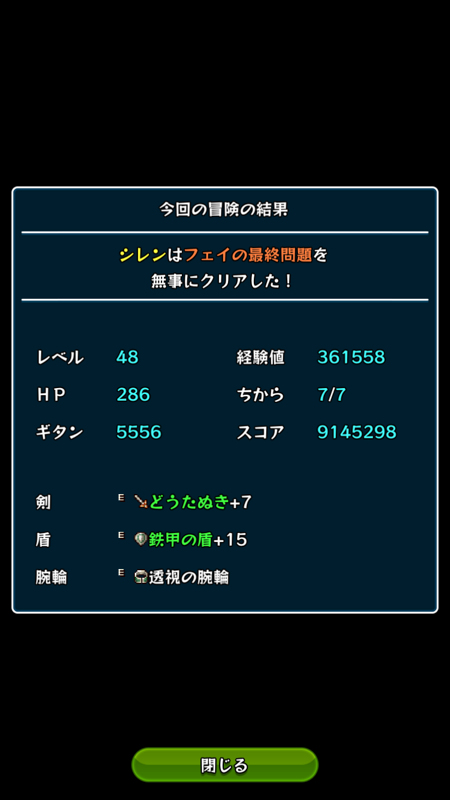
最終装備は↑こんな感じでした。低層でトドを倒したときに、透視の腕輪が出たため、終始それに頼るプレイとなりました。
敵が見えアイテムが見え、これ引ければほとんど勝ちみたいな装備でした。
装備をより詳細に見ると下のような感じで、修正値はともかくとにかく印に恵まれた冒険となりました。
まず盾がこれ。
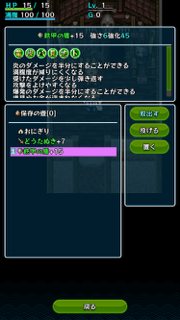
何と6つも印がつきました。竜皮バ見地トと、欲しいものがほとんど揃っています。
剣はこれ。
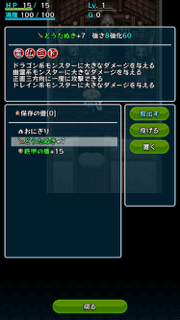
竜仏三ドと、盾に比べて若干寂しく見えますが、十分でしょう。
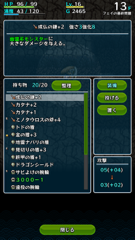
いつこんな装備を完成させられたのか? というのがポイントですが、盾については下記の通り材料は13F時点でほとんど揃っており、合成の壺も割とすぐに出てくれたため、かなり早い段階で装備の印がほぼほぼ完成した感じです。
・雑感
スマホ版風来のシレンはDS版をスマホに移植したゲームです。
DS版はSFC版と比較して不人気であり、攻略情報も少ないため、プレイし始めの頃は不安が多かったですが、実際にプレイしてみると杞憂に終わったといえます。
確かにペンペンのような嫌がらせモンスターが追加されたのは嫌なところですが、逆に言うとそれくらいなものではないでしょうか。
あとはゲイズの異様な催眠率と乱れ大根がファッキンってところでしょうか。
DS版ではSFC版に見られた、いわゆる「36Fの壁」がなくなり、ダメージ計算式も減算式となったことから、盾の修正値を鍛えることに絶対的な意味があるバランスではなくなり、総合的に見て遊びやすくはなっているのではないでしょうか。
もちろん、その点をもって、味がなくなってしまったという見方もあるでしょう。
(当方SFC版未プレイなため、これ以上は何とも言えないところですが。。。)
今回は低層で装備がほとんど揃い、かつ透視まで引いてしまったので、容易に勝つことができました。
私見ではありますが、このゲームは、多くのRoguelikeゲー同様、序盤ゲーという印象が拭えません。
装備がまともに揃わない丸裸同然の低層で多くループし、そこを抜けられると一気にゲームが容易になる。
そういうバランスになっている気がします。
下の番付を見る限り、20F以降に進めたのがおそらく今回のプレイが初だった可能性が高いのですが、
そんな状態でもあっさり99Fにたどり着けてしまいました。
まさにチートの透視+しっかりした装備が早くに完成した点が大きいと思いますが、
HPがちゃんと自然回復するという点も大きかったと思います。
後作のシレンでは、後半まともに自然回復しませんので、それと比較すると、真逆のバランスという印象です。
明日の記事は、水暇氏の「変愚勝手版:変容ハイメイジのプレイ記事」です。
DCSSの昔を振り返る
本記事は、「DCSSの昔を振り返る」と題したRoguelike Advent Calendar 2021 - Adventar12/13の記事です。
最近あまりDCSS(Dungeon Crawl Stone Soup)をプレイできておらず、最新バージョンについていけていない感がありますが、今までDCSSをプレイしてきて、どう更新がされてきたのか振り返ってみたいと思います。
DCSSは大変更新が激しいゲームであり、すべてについての説明は到底できませんし、筆者がプレイし始めたのはver0.13なので、それ以前の説明はできません。ご了承ください。
- ver0.13
最もインパクトのあったのは、新種族Gargoyleの追加と言って満場一致ではないでしょうか。低HP種族というデメリットはあるものの、毒免疫・腐敗耐性、絶縁、耐負、苦痛耐性、特定のLvから飛行、LvアップによるAC上昇と、とんでもなく強い種族です。
AC上昇は、何の装備制限もないのに、Lv27で+20もブーストされ、とてつもなく硬くなります。
ちなみに、筆者が初めてDCSSを脱出したときの種族はGargoyle(15ルーン初脱出もGargoyle)であり、なかなか脱出できない初心者の方は、一度使ってみるといいのではないでしょうか。
- ver0.14
このバージョンでも新種族が追加されました。Formicid(蟻)とVine Stalker(蔓生物)の2つです。
Formicidは常時停滞(加速・減速・麻痺の影響を受けない、teleport, blinkが不可)という緊急回避に難がある種族ではありますが、代わりに壁を掘ることができるほか、両手武器(弓、クロスボウを含む)と盾を両立することができるという反則的な種族特性を持っています。
スキル適性もよく、極めて強力な種族の一つです。
Vine StalkerはHPを薬やワンドで回復することができず、また低HP種族(-30%)というデメリットを持っていますが、代わりにHP自然回復量が高く、また、守護霊(被ダメをHP/MPに分割)がついています。殴りの際、確率で追加攻撃としてアンチマジックの牙が発動し、MPを回復できてしまいます。
要するにどういうことかというと、一見HPが少ないように見えるが、MPまで含めてHPとして計算できるので実際に低耐久というわけではなく、
殴りを続けることで、MPを回復できるので、実質的には吸血攻撃となっているという、完全なインチキの領域に踏み込んでいます。
しかも、追加攻撃のダメージがなかなか強烈なので、クイックブレードを持たせると何もかもを切り刻む恐ろしい植物が誕生してしまいます。
種族だけでなく、信仰も追加されたのがこのバージョンです。
暗殺指向のDithmenosが追加されています。パッシブとして隠密を強力にブーストし、Shadow mimicといって自分の影みたいなものが、自分の近接攻撃や遠距離攻撃を一定確率でまねてくれます。影が近接攻撃をまねることで敵が余所見判定となった場合、暗殺が容易になりますし、ここでいう遠距離攻撃は呪術も含みますので、魔法の眠りを影とあわせて合計2回発動できるのが非常に暗殺向きであることは容易にわかるでしょう。
(ただ、暗殺よりも水晶槍やトロルの大岩投擲を影に発動させるビルドの方が強い・・・)
また、祈祷としては、Shadow Stepで寝ている敵の目の前にジャンプできるほか、最終奥義Shadow Stepは非常に防御が優秀な形態で、透明になった上で苦痛免疫をつけ、ダメージ/被ダメージがともに半減されます。敵を倒さずにルーンやオーブを盗むプレイの際、非常に有用です。
新種族以外の変更としては、新呪文があります。純粋に追加されたもののほか、既存の呪文から入れ替わりとなったものもあります。
Ice StormがGlaciateに、Summon DragonがDragon's Callに変更となったほか、Summoning領域に多くのスペルが追加となりました。
- ver0.15
最も大きな変更点として、アイテム重量とアイテム破壊の撤廃があります。
アイテム重量が撤廃されたことで大岩持ち放題、アイテム破壊がなくなったのでいちいち物資を床に置いたりしなくてよい、と、ゲームの遊び方が大きく変更となりました。
煩雑な部分が解消されたわけですが、重量も物資破壊もダンジョンに潜っているのだからあって当たり前だろというフレーバーでした。最近のDCSSはフレーバーを重視しない方向に大きく進化を遂げているのですが、その先駆けとなった変更といえるでしょう。
その他の変更で、特筆すべきは以下3点でしょうか。
1. 負のアンチクロストレーニングの撤廃
→ 従来は、例えば火のスキルを上げていると、反対の領域である氷のスキルには適性に負の補正がかかり、育てにくくなるといった、当たり前のフレーバーがありましたが、なぜか撤廃されてしまいました。
2.Statue FormのEV-10ペナルティ撤廃
→ 多分、「石像形態は減速ペナで十分弱いのでEVペナは要らないよね」みたいな、よくわからない理屈で撤廃された記憶があります。石像はありえないくらい強いのでEVペナはあって当然ですし、石像が俊敏に避けまくるのはどう考えてもおかしいので、その点からもEVペナはあってしかるべしと思うのですが、なぜかEVペナ撤廃。ゲームバランスが明らかに壊された変更の一つです。
3.遠距離武器のダメージ計算統合
従来、弓などの遠距離武器は近接武器と異なる計算でダメージ計算をしていましたが、統合されました。また、投擲がものすごく強化されたのも、このバージョンからだったと思います。
投擲がいかに強いかは、過去の記事で詳しく解説しています。
attogame-tansoubu.hatenablog.com
その他、新神Qazlalの追加など、様々追加点はありますが、解説は省きます。
- ver0.16
数々の変更点はあるのですが、新スペルSingularityに尽きます。Translocation領域の奥義(Lv9魔法)としてこのバージョンで追加され、あまりにゲームバランスを破壊したため、次のver0.17で早くも削除されてしまったという伝説の呪文です。
これが印象に残りすぎて、逆に他に何が変わったか、はっきり言って全く思い出せないレベル。
効果は簡単に言うと、ブラックホールを発生させ、近くの敵に継続ダメージを与えるというもの。
ブラックホールは@の視界外にあっても敵に継続ダメージを与え、ブラックホールがあるうちは吸い込まれている敵はブラックホールの影響を受けてそこから動けないため、魔神クラスの敵すら視界外から封殺することができてしまった、恐ろしく業の深い呪文なのです。
削除やむなし。
その他、新信仰として、GozagとRuが追加されたのがこのバージョンです。
- ver0.17
正直どんなバージョンだったっけ? とあまり記憶に残っていないバージョンです。0.16のマイナーチェンジといった印象ですね。
・・・どんな変更があったっけと見直してみると、jellyが一度@が見たアイテムを食べなくなったバージョンでした。かなり大事な変更ですね。
他の変更は、強いて言うならば、Enslavementの呪文や、ver0.16で追加されたShadow trapが削除されたことくらいでしょうか。
- ver0.18
ver0.15で投擲が大きく強化されましたが、その調整が入ったのがこのバージョンです。通常の武器と同様の速度計算となりました。
大岩を例で説明すると、ver0.15ではスキル0でも1ターンで投げられ、スキルを育てることで最速0.5ターンに到達したのですが、
ver0.18からは、スキル0では2ターンかかり、スキル27で最速0.7ターンに到達する計算となりました。
大岩投擲は強すぎたのでやむを得ない変更と言えます。変更後でも十分すぎるほど強いですしね。
また、wandやamuletの種類に大きく変更が入ったのがこのバージョンであり、特にamulet of resist mutationが削除されたことにより、
後半の変異対策が難しくなりました。
このように、全体的に難易度がしょっぱくなった印象のバージョンです。
その他、発動の信仰としてPakellasが追加されたのですが、なぜか次のバージョンで早くも削除されてしまいました。
最終的に回復、テレポ、加速のワンドが使い放題となってしまうのが問題視されたのでしょうか。経緯は今となっては不明です。
- ver0.19
非常に遊びやすく、一定完成されたバランスのバージョンと思っています。日本語版DCSSのバージョンもこれです。
長剣に反撃(Reposte)といった特性が追加されたのが最大の変更点でしょう。
長剣を装備していて敵の近接攻撃をEVで避けた際、確率でターンを消費せずに長剣で反撃するようになりました。
確率は当初50%でしたが、調整後(0.19内だったか以降のバージョンかは定かでない)33%となりました。
Chei信仰で長剣+石像など試してみるとなかなか面白いでしょう。
その他、Charm領域のHasteが削除され、jellyが一切アイテムを食わなくなったのがこのバージョンです。
新信仰としては、Uskayaw、Hepliaklqanaが追加されました。
- ver0.20
最大の変更は、筆者としてはTombの難易度の上昇と考えているところです。
Tombは従来は階段プレイしているだけで容易に制圧できる分岐でしたが、このバージョンから、1F→2F、2F→3Fにおいて、下り階段で下りた位置に上り階段がない(少々離れたところにある)ように変更され、簡単にクリアさせてくれる分岐ではなくなりました。
Tombの難易度上昇の方向性はこの後のバージョンでも続いていくこととなります。
その他、特筆すべき変更としては、強力な種族Barachimの追加、種族High Elfの削除、Ogreのスキル適性の調整(いわゆるオーガメイジ型の適性に)、呪文Repel Missilesの削除といったところでしょうか。
- ver0.21
DCSS最強種族の一つであるGnollが追加されたのがこのバージョンです。
Gnollは、スキル適性が+6や+8ばかりなど目を見張る成長速度ですが、代わりに一度にすべてのスキルしか鍛えられないという特性を持っています。
性質上、両手武器やLv9魔法を使いこなすのは難しいですが、それ以外の大抵のことは何でもこなせる非常に強力な種族です。
石鍋wikiにもオススメ記事を載せていますので、未プレイの方は是非お試しあれ。
その他、新信仰としてWJCが追加されています。
- ver0.22
PlayerのGhostが、隔離された場所にしか出現しなくなり、非常につまらなくなりました。
従来は、探索中、いつどこでGhostに出会うかわからず、ヒヤヒヤしたものですが、このバージョンからは、Ghostを見かけても必ず隔離されており、自分からドアを開けない限りは襲われることはなくなりました。
なんでこんな変更をしてしまったんだろう・・・本当に謎です。
- ver0.23
罠の仕様が変更され、ゲーム後半(特にZotとTomb)の難易度が大幅に上昇しました。
まず、従来と異なり、罠は完全に見えるようになりました。見えない罠を踏んで不快な思いをすることがなくなりめでたしめでたしと思いきや。
何と、見える罠とは別に、「探索をトリガーとする罠」が追加されました。探索していると一定の確率で罠を踏んでしまうというわけです。
その中身が強烈で、alarm, shaft, teleportの3種となっています。
この変更により、従来と比較して、突然alarmを踏む、突然下の階に落ちるといった不快な事象がしばしば発生することとなりました。
また、見える罠として、dispersal trapが追加されました。踏むと、@と視界内の敵が視界内のランダムな位置にブリンクします。
これが非常に強烈な罠であり、罠は敵が踏んでも発動してしまうことから、突然わけのわからない位置にブリンクさせられ、また敵が踏んで別の位置にブリンクさせられ、とお手玉状態となってしまいます。
特にTomb最下層との相性は最悪です。ただでさえ階段を下りたとき、上り階段は別の位置にあるわけです。必死に上り階段まで歩いても、マミーがdispersal trapを踏むだけで階段から引き離されます。歩かずにblink巻で上り階段まで一気に辿り着いたとしても、その瞬間マミーがdispersal trapを踏むだけで、階段から引き離されてしまいます。
否応なしに、階段プレイとの決別を要求しているわけです。
この変更により、Tombの難易度が15ルーンにふさわしい、恐ろしい難易度となってしまいました。筆者が最近あまり15ルーンをやらなくなった原因の一つがこれです。
- ver0.24
VampireとSif Munaの変更が主な変更点です。
Vampireの仕様変更については、石鍋wikiに詳しく書いたことがあったので、それをぺたっと貼っておきます。(手抜き)
mars.kmc.gr.jp
Sif Munaについては、祈祷で信仰値を削り、スペルを失率0でキャストすることができるようになりました(その際のスペルパワーは祈祷スキルに依存)。
この変更により、例えば召喚魔法を一度も唱えたことがない(スキルも全く鍛えていない)キャラが、Dragon's Callを祈祷スキルだけで詠唱できたりと、非常にプレイの幅が広くなった印象です。
- Ver0.25
火や氷領域の多くの魔法が変更されたバージョンです。
火領域→Lv1魔法がFoxFire(Flame Togueが削除)、Lv6魔法がStarbust(Bolt of Fireが削除)となりました。ついでにThrow Flameも削除されています。
氷領域→初期本だけでなく、Lv9魔法を含め、大幅に変更されました。Lv9魔法はAbsolute zeroに変更となりましたが、DCSSにおける伝説の魔法と考えています。何と効果は、射程内で最も近くにいる敵(複数いる場合はランダムに選択)を問答無用で即死させるというものです。TRJだろうがLom Lobonだろうが、お構いなしに即死させます。ひどい。
あまりの酷さに後のバージョンで削除されました。
なお、火や氷に限らず本バージョンでは多くの魔法が調整されました。RegenerationやDeflect Missilesといった有用なバフ魔法も削除されてしまいました。
- Ver0.26
このあたりから変更をあまり追えていません。
筆者が認識できているのは、食料システムが完全に撤廃されたこと、Charm領域自体がなくなったこと、沼分岐に数多くの新敵が現れ、一気に難易度が上昇したことくらいです。
また、名物種族の一つであったCentaurが削除され、新種族に入れ替わりとなりましたが、プレイ経験がほとんどなく、どういった種族なのか理解できていません。
- Ver0.27
現行安定バージョンです。HPとMPが共通で、完全にランダムで魔法を習得する(代わりに魔法書で魔法を習得できない)新種族Djinniが追加、その他新スペルも多々と、たいへん変更点が多いのですが、すべてを把握できていないのが実情です。
以上、簡単ではありますが、プレイし始めた0.13から現行安定バージョンの0.27までの歴史を振り返ってみました。
明日の記事は、chikatei氏の「ロストリンギル少佐はいかにして大佐に昇進したのか」です。
風来のシレン5 原始に続く穴の魅力を語る
本記事は、
Roguelike Advent Calendar 2021 - Adventar
2日目の記事です。
前回の記事で書きましたが、最近風来のシレン5に再度ハマり始めたので、今回の記事ではそのことについて書きます。
「再度」というのは、風来のシレン5(DS版)を買った当初も当然ハマっていたのですが、いわゆるもっと不思議のダンジョンである「原始に続く穴」が99Fまで攻略できず、長い間(4年ほど)積みゲーとして放置したままだったのです。ところが、最近steamやswitchでリマスターされるなど、比較的活気のあるゲームとなってきており、触発されて久しぶりにやり始めたらまたはまり始めたという経緯です。
ダンジョンの前に軽く作品自体の解説をします。
風来のシレン5は大変人気がある作品で、初心者に優しいつくりとなっています。
具体的には、ポイントショップでやりなおし草や復活草を買えたり、装備にタグをつけることができたりします。前者は文字通りの残機として機能し、後者は死亡やその他の装備ロストの際、タグ屋に失った装備が届く仕組みとなっています。これらの仕組みにより、ストーリーのクリアが比較的容易です。また、丁寧なチュートリアルもあり、ゲームに慣れることは比較的容易と考えられます。
一方で、持ち込み不可のもっと不思議のダンジョンの難易度は健在(それでも過去作よりは易化らしい)であり、長年シレンを楽しんできた人にもやり込みがいのあるゲームとなっていると思われます。
自発的挑戦ことエキスパート証明書を埋める楽しみもあります(壺を使用しないでクリアしろ、など)。
本記事はシレン5を代表するもっと不思議のダンジョンである「原始に続く穴」の魅力を語る記事ですので、魅力を書いていきたいところですが、概ね以下に集約されるのではないでしょうか。
- 低層ループの排除
Roguelikeゲームは、往々にして装備やアイテムが揃わない序盤が最も難しいバランスになりがちです。
一方で、本作(原始に続く穴に限らない)は賛否はあるものの、以下の仕様を採用しています。
「序盤の最大HPが低い頃はHPの自然回復が極めて早く、最大HPが伸びるにつれ、自然回復が遅くなっていく」
最序盤はHPが2ポイント近く自然回復しますので、裸でもピラーダンスで容易に生き延びられるようになっています。一方で中盤以降は、足踏みをしてもまともに回復しませんので、ガチガチに殴り合って足踏みで回復させて、みたいな脳筋プレイが難しくなっています。回復アイテムの重要性も増しています。
大変違和感のある仕様という声も多いですが、ゲームバランスが大幅によくなっているのは確かと思います。
(ロープレ的に序盤のサバイバルを楽しみたい人には向いていません。)
- 盾から剣へ、装備の成長
過去作のシレン(4は除く)は盾ゲーと言われ、とにかく盾の修正値を鍛えることに重きが置かれていました(特に初代やアスカ見参など)。
一方本作ではバランスが大きく変更され、盾の修正値を鍛えても目立つほどの影響はなく、むしろ武器を合成により鍛え、素早く敵を倒すことが重要となりました。
特効印をつけ、矢などとあわせてとにかく素早く敵を処理することが、結果的に被ダメの減少に繋がるというわけです。
また、状態異常印というものも存在し、例えば敵を殴ると確率で混乱させたりするようなものもあります。
加えて、本作では装備に熟練度が存在し、成長するようになっています。
4以前の過去作では装備は成長しませんので、基礎値が高くメインのベースとすべき装備、基礎値が低いため印として合成すべき装備が固定化されており、装備の自由度はあまり高くなかったのが実情かと思います。
装備が成長する本作では、例えば水斬りの剣は印として合成するだけであれば、水棲の敵に1.35倍ダメとなるところが、メイン剣として運用し、MAXレベルまで育つと3.1倍までダメージが上昇します。混乱の手斧であれば、印として合成するだけでは12%の確率で敵を混乱させるところが、メイン斧として運用すれば、28%の確率で敵を混乱させられるようになります。
このように、装備を成長させると、単に印として合成するよりも強くなっていくため、どういった武器をメインとして運用するか、
非常に自由度が高くなっており、毎回のプレイの楽しみの一つでしょう。
- 豊富な勝ち筋
上述の通り、武器の選択一つとっても選択肢が非常に多いゲームであり、とにかく本作はプレイヤーの選択肢を増やし、自由度を高める方向性となっています。
過去作のように、「これ引けなきゃ死」という状況は少なく、強力なアイテムも多いので、
「○▲×□のうち~が引ければこう進む、~~が引ければこう進む」みたいな戦略が立てやすいのです。
序盤の難易度がHP自然回復の仕様により低いため、元々床落ちアイテムが比較的多いバランスということもあり、
何らか強力なアイテムを引けることは多く、「ゲームにならずに一方的にボコられて死」ということは起こりにくいのではないかと思います。
最終的に99Fまでたどり着けなくても、何となくゲームをやった気になれます。
筆者は、最近ようやく「原始に続く穴99F」をクリアできたばかりであり、まだまだこのダンジョンへの理解度が
高いとは言えませんので、解説はここまでとします。
(誰かカレンダーで、続きの記事を書いてくれれば大変筆者が喜びます。)
まずはクリア回数を増やし、徐々にエキスパート証明書などの自発的挑戦にも挑戦できれば、と思っているところです。
ちなみに、初勝利時の装備はこんな感じでした。(画像には出ていませんが、気配察血あり)


不思議のダンジョン歴を語る
本記事は、
Roguelike Advent Calendar 2021 - Adventarの12/1分の記事です。
変愚やDCSSなど、元々RoguelikeはPCゲーをやることが多かったのですが、
いわゆるトルネコの大冒険や風来のシレンに代表される「不思議のダンジョン」系のゲームにも
触れる機会があったので、どんなゲームをやってきたか思い出しながらまとめてみます。
結局クリアしていないゲームも含みます。
- トルネコの大冒険3(ストーリー未クリア)
不幸なことに私が触れた最初の「不思議のダンジョン」ゲーです。
プレイ当時は、それがRoguelikeゲーという認識もなく、ちょっと変わったDQとして
遊んでいました。それも当然、トルネコ3はレベル継続性のため、ぱっと見て普通のRPG
と変わりません。
面白いなと思ったのは、ポポロ編でモンスターを仲間にしながら進めるところで、
ぶっちゃけそれくらいでした。
なお、ストーリーは結局クリアできませんでした。
このゲーム、ラストダンジョン手前で、突然特定の地域に閉じ込められ、ラストダンジョンを
クリアするための装備や物資を手に入れるのが困難になります。
要するにDQのくせに初見殺しの詰みというものが発生する、恐ろしいゲームであり、
実に評判が悪いゲームだ、ということを大人になってから知ることとなります。
機会があればもう一度やり直し、いわゆる「もっと不思議のダンジョン」である
「異世界の迷宮」に挑戦したいところです。
ストーリーすらまともにクリアできていないため、これ以上何も語ることが
できません。
- チルノ見参(ストーリークリア、「慧音の最終問題」クリア、「最強への道」未クリア)
私が「不思議のダンジョン」ゲーにハマるきっかけとなった、
大変思い入れの深いゲームです。
どうやってこのゲームを見つけたのかは思い出せません。
このゲームの特色は以下です。
わかる人には「ディアボロの大冒険」に似たシステムと言うとわかりやすいかもしれません。
1.決まり切った「武器」「防具」というアイテムではなく、
カードを武器や防具として装備する。(武器にも防具にも装備できる)
例えば、「レミリアのカード」であれば攻撃力10,防御力4のカードですので、
武器として装備すれば攻撃力10の恩恵を、防具として装備すれば防御力4の
恩恵が得られます。見ての通り、攻撃力が高いため、武器として使うことが
普通のカードですが、システム上、一応防具としても使用できるわけです。
普通のRoguelikeゲーでは、武器は武器、防具は防具でしかありませんが、
このゲームでは、カードは武器としても防具としても使えます。
ですので、普通のRoguelikeゲーでよくある
「序盤武器は出たけど盾が出ずに紙装甲で死にそう」
とか
「盾は出たけど武器がなくて殴りが弱い」
ということが少ない仕様となっています。
カードは武器としても防具としても使えるため、2つ拾えばそれぞれ武器、防具
として使えるわけです。
低層ループが嫌いということもありますが、
固定化された武器、防具ではなく、武器としても防具としても
使えるという設計に、当時の私は美しさを感じました。
2. カードには発動効果があり、修正値を削って発動できる
武器としても防具としても使えるだけでも凄いと思っていたところに
カードは修正値を削って発動できると知りました。
凄いと思いました(小並感)。
装備としてはイマイチでも、発動効果が強いカード
(例えば「ナズーリンのカード」は、攻撃力4防御力3と貧弱ですが、
発動効果は「フロアのマップ、階段、アイテムの位置を明らかにする」と非常に強力)
もありますし、
どのカードを強化していくか、プレイヤーをほどよく悩ませる設計となっています。
3.「なんでも装備」システム
おにぎりも巻物も草もカードも、なんでも装備できる!
強すぎちゃうのっていうシステムです。
武器、防具以外に「なんでも装備」の枠が3つあり、文字通り「なんでも装備」
できてしまいます。
例えば、「薬草」を「なんでも装備」すれば、
敵を殴ったときに4ダメージHP回復、敵からダメージを受けたときに4ポイントHP回復
するようになります。
「毒消し草」を「なんでも装備」すれば、ちからの低下を防ぐことができます。
例として「草」の「なんでも装備」を挙げましたが、
草以外に巻物やカードも装備することができます。
例えば、「レティのカード」は防具として装備した場合、HPの自然回復速度が1.5倍に
なる効果がありますが、「なんでも装備」した場合でも同様の恩恵が得られます。
防具は他の基礎値が強いカードを装備しておき、特殊効果が強いカードは
「なんでも装備」する、といった運用ができるわけです。
「不思議のダンジョン」ゲーに詳しい人は、この説明を読み、
これは「合成システム」ではないかと気づいたのではないでしょうか。
その通り、これは、合成の機会を待たずして合成の恩恵を受けることができる
仕組みとなっています。強すぎでしょう。
4. アイテムが「凍る」仕組み
3.で説明した「なんでも装備」があまりにも強すぎるため、
バランスを取るため、アイテムが10階層過ぎると「凍る」ようになっています。
「凍る」と、「なんでも装備」することができなくなりますので
永続的に欲しい能力は、「なんでも装備」に頼らず、合成してしまった方がよいのです。
例えば、薬草を「なんでも装備」すれば、殴ったときとダメージを受けたときに
それぞれHPが回復しますが、これはどう考えても永続的に欲しい能力ですので、
武器、防具に合成したいところです。
ただし、「なんでも装備」であれば、薬草1つで攻撃時、被攻撃時HP回復が得られますが、
合成する場合は、武器に合成した場合は攻撃時のみ、防具に合成した場合は被攻撃時のみ
HPが回復するので、「なんでも装備」と同じ恩恵を受けるには、薬草を2つ見つける必要
があります。
アイテムは階層の経過により凍ってしまいますが、解凍の巻物というアイテムで元に戻す
ことができますし、凍ったアイテムを元に戻す攻撃をしてくる敵も出てきます。
いわば「火炎入道」のオマージュです。
ですので、あえて薬草を合成せず、「なんでも装備」をフル活用し続ける、といった戦略も
考えられます。
「なんでも装備」への対抗バランスとして考えられた「凍る」システムですが、
非常に美しいシステムと感じられます。
東方のキャラクターであるチルノが氷を操る能力を持っていること、
凍ったアイテムを解凍する攻撃をもつ敵を、いわば「火炎入道」のオマージュとして
実装できること。ゲームバランスがどうというより、この2点が、
東方のゲームとして、そして、「不思議のダンジョン」ゲーとして、
非常に美しい。
作者はよく考えたなーって感じですね。
思い入れのあるゲームですので、解説が長くなってしまいました。
思えば、私が「不思議のダンジョン」にはまり始めたのは、このゲームがきっかけです。
(変愚やDCSSに比して)強力なアイテム(カードの発動を含む)、合成システム、
「なんでも装備」システムといった、システム面での魅力が多数あるゲームです。
「矢稼ぎ」や「ニギライズ」といった「不思議のダンジョン」ゲーの必須テクニック、
モンスターテーブルを見て、厄介な階層への対策を考えるといった基本的な考え方を
学んだゲームでもあります。
99F持ち込み不可ダンジョンである「慧音の最終問題」にのめりこみ、クリアするために、
元ネタと考えられる64シレンやアスカ見参のwikiを読み、結果として元ネタである
風来のシレンへのめり込んでいくきっかけとなったゲームでもあります。
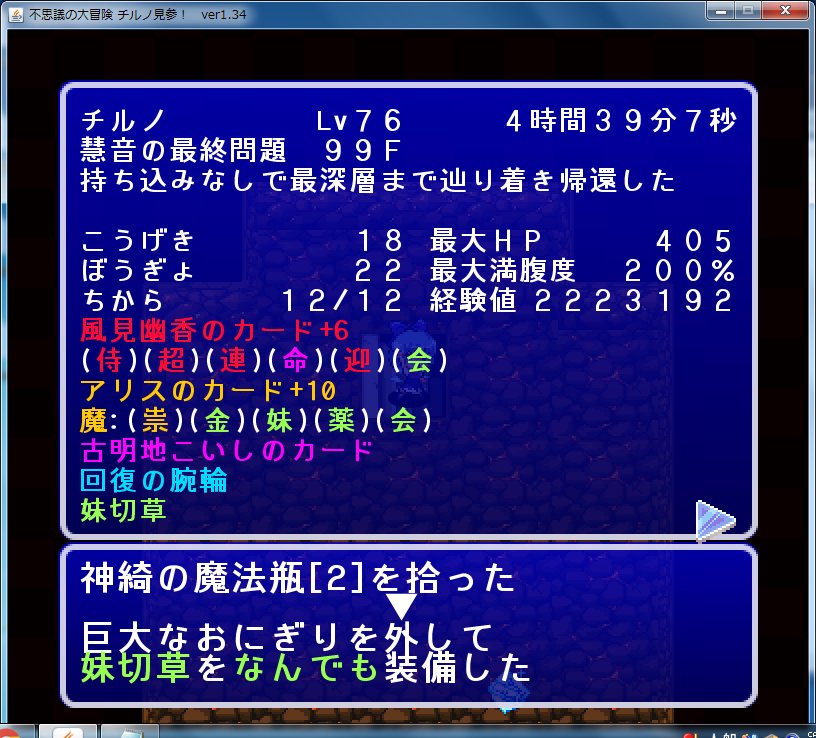
打開したときのSSを貼って、チルノ見参の解説を終わります。
(実は1回クリアして満足しており、それ以降ほとんどプレイしていません)
- タクティカルダンジョン(未クリア)
チルノ見参と並んではまったゲームです。悲しいことに作者のサイトが消失してしまっていますが、
ゲーム自体のダウンロードはまだ可能と思います。
ゲームの特徴として、SRPG×不思議のダンジョン という感じです。
SRPGの要素を持つため、なんと1ターンで移動と攻撃の両方を行うことができます。
移動距離が短い敵もいるので、そういった敵にはヒットアンドアウェイを繰り返すことで
ノーダメージ撃破できるといった、不思議のダンジョンとしては珍しい特徴をもったゲームです。
このゲームにはまったのは以下の理由によります。
□1フロアが14×14マス(15だったかもしれない)しかなく、ゲームの展開がサクサク進む
□合成システムが面白い
合成を進め印を集めていくと、複数の印が1つの上級印にまとまることがあったり、
また、ベースとなる装備も、より強い別のものに進化する場合があること。
このゲームの最大の魅力といっても過言ではないでしょう。
今回はどんな強力な装備を作れるだろうかと毎回わくわくしていました。
強力な装備を作れたときのカタルシスは、合成の難しさ(いわゆる合成は「怪盗ペリカン」システム)もあって
このゲーム特有のものです。
- チルノ見参2(ストーリークリア)
チルノ見参1が面白かったので、2も買ってプレイしていました。
1はシステムとして美しいとは言ったものの、バランスは若干荒削りなところがありました。
アイテムの種類やカードの効果等を見直し、より細かくバランスを調整したのが2といえます。
ダンジョンも多く、すべてをやり込むには大変時間がかかるといえるでしょう。
実は何個か持ち込み不可ダンジョンの易しいモードをクリアした程度しかまだプレイしておらず、本格的な解説は書きにくいところです。
そんななかでこのゲームで最も画期的と感じた点は以下です。
なんと、罠のある可能性のあるマスが、他のマスと違う表示!!
「不思議のダンジョン」ゲーはとかく罠チェックが煩雑ですが、
チルノ見参2では、あらかじめ罠のある可能性のあるマスをプレイヤーに提示
することで、この問題を解消しています。
罠の仕様を始め、ゲームをプレイする上で煩雑と感じやすい部分が多く
解消されており、非常に快適なUIで楽しみやすいゲームです。
- 不可思議なダンジョン2(30Fまで)
とてもマゾい昔のゲームで、30Fまででクリアの2ndダンジョンまでしか
プレイしていません。
食料がラーメンなため、お湯を注いで食べる必要があるといった、他のゲームでは見ない食料システムを採用しているゲームです。
また、満腹度以外に「やる気」というパラメータ(ターン経過で低くなり、階段を降りると
ある程度回復する)があり、これが戦力に直結するため同じ階層に長居できない、
合成は失敗することがあり、失敗すると印が消えたりして弱くなる、
ゲームの後半には強制的に合成してくるゲームが出てくるなど、非常にストイックなゲームです。
核兵器の巻物といったトンデモアイテムがあるのもポイントだったりします。
とにかくマゾく、ストイックなゲームであり、
特に合成が失敗することがあるという点は、合成で強い装備を作って遊びたい筆者には
耐えられない仕様でした。
なので、ちょっと触りはした程度のゲームです。
心に余裕ができたらまたプレイし始めるかもしれません。
- だんえた3(未クリア)
不思議のダンジョンにcrawlやT.o.M.E.のようなスキル制を持ち込んだら?といった
コンセプトのゲーム。
最初に「ヴァルグリンド」や「バスラム」といったキャラクターを選ぶことができ、
それぞれのキャラクターは固有のスキルツリーを持っています。
スキルもすべては取れないので、どこを伸ばしていくか、それを
アイテム等の引きに応じて考えていく、といったゲームです。
UIが快適(店主に話しかけると、未識別の持ち物に自動で値札をつけてくれるなど)なため
サクサク進むゲームではあるのですが、難易度が高く、サクサク死ぬゲームでもあります。
クリアできていないため、これ以上あまり書くことがありません。
今年のカレンダーで誰か続きを書いてくれるのを期待しています。
- 風来のシレン5(「原始に続く穴99F」ようやく1回クリア)
PC系の同人ゲーで「不思議のダンジョン」ゲーの面白さに目覚めたので、
本家本元をやってみようと思って買ったのが風来のシレン5(DS版)。
最近はsteamやswitchでも出て、賑わいのあるゲームでもありますね。
次の記事で詳しく書きたいと思います。
初代のシレン(DS仕様)がスマホに移植されたので、買ってみました。
テーブルマウンテン素潜りをイベントを進めながら何度目かの挑戦で無事達成し、全滅の巻物を解禁したところで
いざフェイの最終問題を・・・と思って低層ループに励んでいるところです。
(シレン5と比較するとどうしても低層ループしがちなんですよね)
スマホゆえの操作性の悪さはありますが、手軽にプレイできるのは
いいのではないでしょうか。(手軽にプレイできるゲームではない気がするものの・・・)
- ドラゴンファングZ(未クリア)
「一歩を踏み出す勇気!」が掛け声の、特異なゲームです。
通常のRoguelikeゲーは、広間でなく通路で戦うのが基本中の基本ですが、このゲームは、ブレイブシステムという特殊なシステムを採用しており、広間で戦うインセンティブをプレイヤーに与えています。
どういうことかと言うと、モンスターの牙というものを全てのモンスターが確率で落とし、装備することで牙のスキルを発動できるのですが、スキルをチャージする方法が、「周囲8マスに壁などの障害物がない状態で敵を攻撃する」ことなのです。牙のスキルを活用するのが根幹のゲームバランスなのですが、そのためには一定リスクを取って広間で戦う必要があるというわけです。また、広間で戦い続けると、ブレイブゲージというゲージが溜まっていき、一定ゲージがたまると特殊な効果を発揮する武器も存在します(前方3方向に攻撃できるようになるなど)。「一歩を踏み出す勇気!」、なんとこのゲームを的確に言い表した言葉なのでしょうか。
最初のストーリーダンジョンすら自分の腕では素潜りきつすぎるので、持ち込んでクリアしようかなと思っても、ゲームへの理解が圧倒的に足りず、持ち込みありでもクリアするビジョンが見えていない状態です。何があれば勝てるのかがわからない。
面白いゲームだしクリアしたいところです。
その他にもプレイした「不思議のダンジョン」ゲーはあるのですが、
記事に書けるほど記憶に残っていないこともあるため、割愛します。
今回の記事はここまでです。
次回の記事では、最近再度ハマり始めた風来のシレン5(のもっと不思議ダンジョン)について書きたいと思います。
内部結合と副問い合わせの違い
2つのテーブルがあるとする。
テーブルraces
+------+ | race | +------+ | Mi | | DE | | Ce | +------+
テーブルbuilds
+------+------+------+ | race | job | god | +------+------+------+ | Mi | Tm | Chei | | Mi | Fi | Chei | | Mi | Mo | Chei | | Mi | Gl | Chei | | Mi | Be | Trog | | DE | Cj | Vehu | | DE | FE | Vehu | | DE | EE | Vehu | | Sp | En | Gozag| | Vp | En | Kiku | | Fe | Mo | Kiku | +------+------+------+
テーブルracesは何となく種族を並べたテーブルで、主キーは種族。というか主キーしかない。
テーブルbuildsは何となくプレイしそうなビルドを並べたもので、主キーは(race,job)で信仰は一つの(race,job)に対して一つにしている。
racesテーブルに書いてある種族のうち、Cheiに向いてそうな種族を抽出したい。
select races.race from races, builds where races.race = builds.race and builds.god = 'Chei';
こう書くと2つのテーブルを結合した後に、Cheiにヒットするものを抽出する。結果はこうなる。
+------+ | race | +------+ | Mi | | Mi | | Mi | | Mi | +------+
Miが一杯だ。テーブルbuildsとの結合に使ったキーraceがMiが4つあるからこうなってしまう。
distinct句を使うと一行だけ出力させられる。
副問い合わせを使うと最初から一行だけになる。
select races.race from races where races.race in (select builds.race from builds where builds.god = 'Chei');
じゃんけんプログラム 入力してCPUと戦う
コマンドライン引数で規定回数を設定し、引数を与えなかったら規定回数を設定しないというのをやりたかった。
max_count=∞とかいう書き方ができないので、例外処理で誤魔化している。
意図的に例外を起こしうるようなコード書かずにmax_countが定義されない条件で条件分岐させたほうがいいのか?
import random import sys count_win = 0 count_lose = 0 count_draw = 0 count = 0 tmp = ['g', 'c', 'p'] judge = { 'g':'c','c':'p','p':'g' } my_list = [] cpu_list = [] try: if len(sys.argv) > 1: if int(sys.argv[1]) >= 1: max_count = int(sys.argv[1]) else: print('cmd引数を無効として進める') except ValueError: print('cmd引数を無効として進める') print('game開始\n') while True: my_jank = input() if my_jank == 'stop': break if my_jank not in tmp: print('正しく入力せよ\n') continue count += 1 cpu_jank = tmp[random.randint(0,2)] my_list.append(my_jank) cpu_list.append(cpu_jank) if my_jank == cpu_jank: count_draw += 1 print('引き分け\n') elif cpu_jank == judge[my_jank]: count_win += 1 print('勝ち\n') else: count_lose += 1 print('負け\n') try: if count == max_count: print('規定回数に達したのでゲーム終了です\n') break except NameError: pass print('win:', count_win, 'lose:', count_lose, 'draw:', count_draw) print(my_list) print(cpu_list)